You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
|
|
7 months ago | |
|---|---|---|
| src | 7 months ago | |
| static | 7 months ago | |
| .gitignore | 7 months ago | |
| .python-version | 7 months ago | |
| README.md | 7 months ago | |
| pyproject.toml | 7 months ago | |
| uv.lock | 7 months ago | |
README.md
基于reAct范式实现的agent
本项目用于验证语音控制大屏后端模块。获取用户输入后,由LLM进行意图识别,并通过function calling调用相关函数,实现语音控制大屏。 使用的LLM是阿里开源QwQ-32B,模型特点为有一定的推理能力并且运行速度快。DeepSeek-R1由于不是天生支持function calling所以不考虑。
function calling 原理:
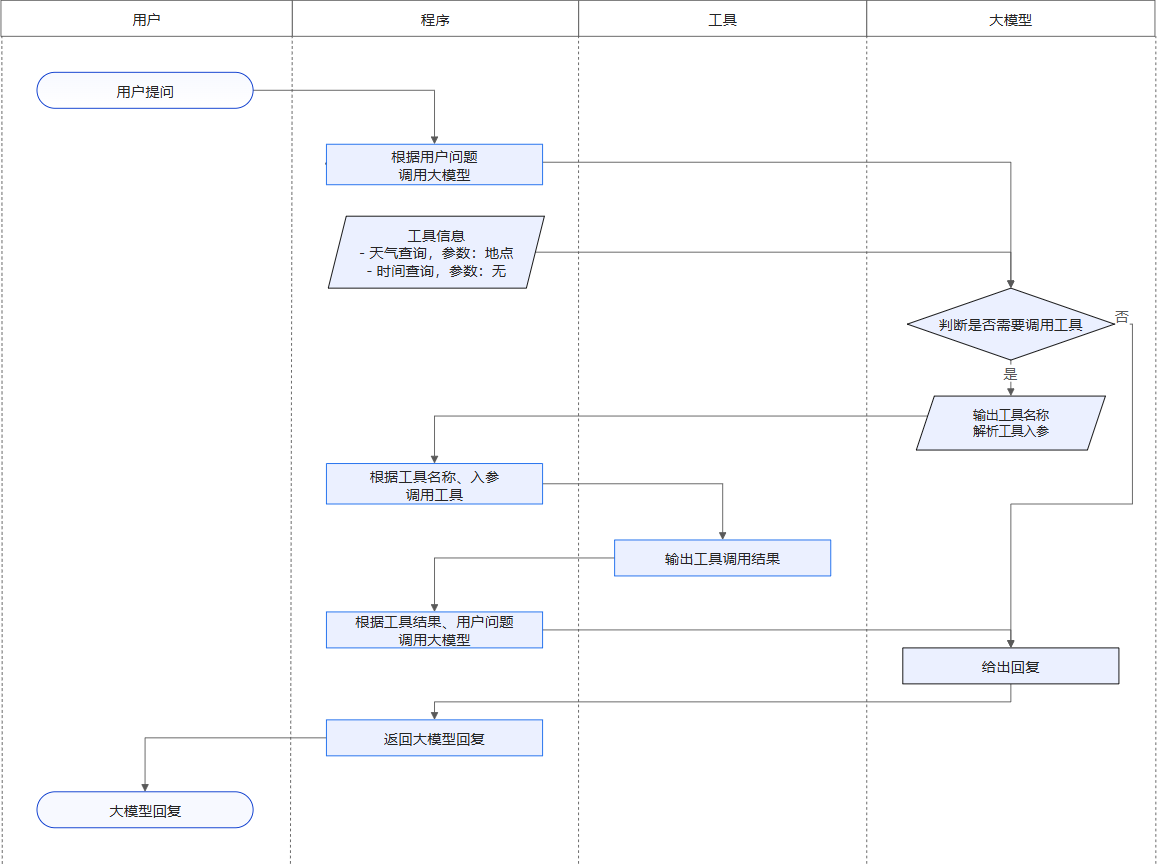
环境搭建
- clone 本项目
git clone http://1.14.96.249:3000/old-tom/reActLLMDemo.git
- 安装依赖 推荐使用uv创建虚拟环境,python版本为3.12及以上
uv sync
3.向量库部署和初始化 (docker)
注:向量库使用marqo,嵌入模型为hf/e5-base-v2,相似度查询效果不太好。
docker run --name marqo -it --privileged -p 8882:8882 --add-host host.docker.internal:host-gateway marqoai/marqo:latest
初始化:执行vector_db.py create_and_set_index()方法
测试:执行vector_db.py query_vector_db() 方法,参数为任意字符串
4.配置文件 env.toml
[base]
# 向量库相似度阈值
similarity_threshold = 0.93
# 模型供应商
model_form = 'siliconflow'
####### 模型配置 #######
[siliconflow]
# 硅基流动
# 密钥
api_key = ''
# 模型名称
model = ''
# API地址
base_url = ''
# 最大token数
max_tokens = 4096
# 温度系数
temperature = 0.6
# 是否流式返回
streaming = true
本地测试
环境搭建完成后,本地运行local_test.py 即可在终端体验对话
服务端简单实现
服务端使用fastapi实现,启动server.py 即可, 完整接口文档请访问 http://ip:port/docs
-
建立sse连接,用于接收模型返回(流式) [GET] http://ip:port/sse/{client_id}
参数:client_id: 客户端ID,用于区分不同客户端及历史聊天
-
请求对话 [GET] http://ip:port/chat/{client_id}?ask=xxx
参数:client_id: 客户端ID,用于区分不同客户端及历史聊天 ask: 请求内容
系统提示词
QwQ-32B 提供了三档推理模式
低推理努力:你思考和回答用户查询的时间极其有限。每多一秒的处理和推理都会产生巨大的资源成本,这可能会影响效率和效果。你的任务是在不牺牲基本清晰度或准确性的前提下优先考虑速度。提供最直接、简洁的答案。除非绝对必要,否则避免不必要的步骤、反思、验证或改进。你的首要目标是提供一个快速、清晰和正确的答案。
中等推理努力:你有足够的时间思考和回答用户的查询,从而给出更周全和深入的答案。然而,要知道你推理和处理的时间越长,相关的资源成本和潜在后果就越大。虽然你不应该仓促,但要在推理深度和效率之间寻求平衡。优先提供一个深思熟虑的答案,但如果通过合理的分析就能提供答案,就不要过度思考。明智地利用你的推理时间,专注于提供准确答案所必需的东西,避免不必要的拖延和过度思考。
高推理努力:你有无限的时间来思考和回答用户的问题。不需要担心推理时间或相关成本。你的唯一目标是得到一个可靠、正确的最终答案。可以从多个角度探索问题,并在推理中尝试各种方法。这包括通过尝试不同的方法进行推理反思、从不同方面验证步骤以及根据需要重新思考你的结论。鼓励你花时间彻底分析问题,及时反思你的推理并测试所有可能的解决方案。只有在经过深入、全面的思考过程后,你才应该提供最终答案,确保答案正确且有充分的推理支持。
可以修改 init.py 中的提示词,默认为中等推理努力
todo
- 替换向量库并升级嵌入模型为bge-m3